What is NOS?
NOS (torch-nos) is a fast and flexible Pytorch inference server, specifically designed for optimizing and running lightning-fast inference of popular foundational AI models.
Optimizing and serving models for production AI inference is still difficult, often leading to notoriously expensive cloud bills and often underutilized GPUs. That’s why we’re building NOS - a fast inference server for modern AI workloads. With a few lines of code, developers can optimize, serve, and auto-scale Pytorch model inference without having to deal with the complexities of ML compilers, HW-accelerators, or distributed inference. Simply put, NOS allows AI teams to cut inference costs up to 10x, speeding up development time and time-to-market.
⚡️ Core Features¶
- 🔋 Batteries-included: Server-side inference with all the necessary batteries (model hub, batching/parallelization, fast I/O, model-caching, model resource management via ModelManager, model optimization via ModelSpec)
- 📡 Client-Server architecture: Multiple lightweight clients can leverage powerful server-side inference workers running remotely without the bloat of GPU libraries, runtimes or 3rd-party libraries.
- 💪 High device-utilization: With better model management, client’s won’t have to wait on model inference and instead can take advantage of the full GPU resources available. Model multiplexing, and efficient bin-packing of models allow us to leverage the resources optimally (without requiring additional user input).
- 📦 Custom model support: NOS allows you to easily add support for custom models with a few lines of code. We provide a simple API to register custom models with NOS, and allow you to optimize and run models on any hardware (NVIDIA, custom ASICs) without any model compilation or runtime management (see example).
- ⏩ Concurrency: NOS is built to efficiently serve AI models, ensuring concurrency, parallelism, optimal memory management, and automatic garbage collection. It is particularly well-suited for multi-modal AI applications.
🏗️ Architecture¶
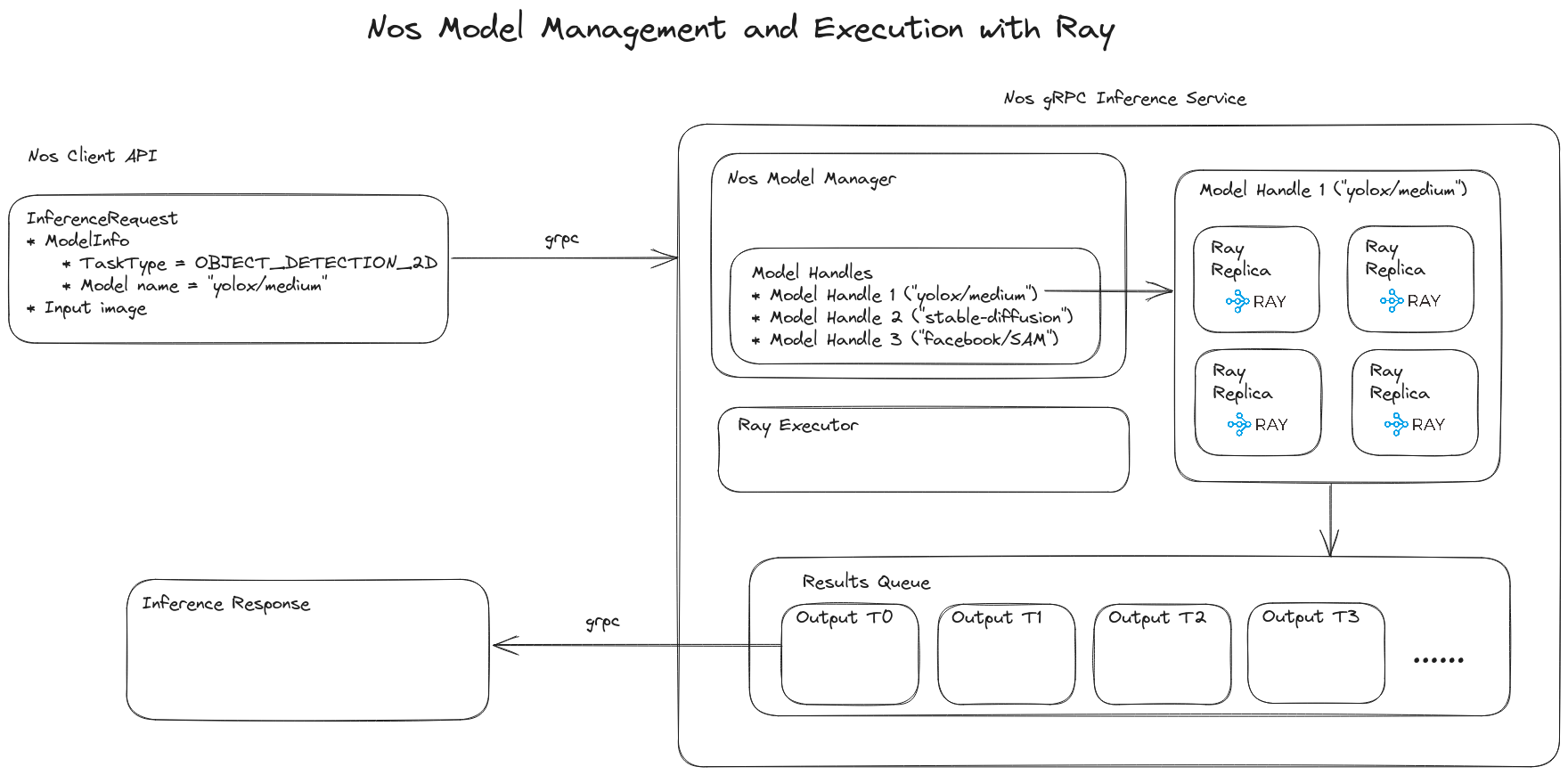
🛠️ Core Components¶
NOS is built to efficiently serve AI models, ensuring concurrency, parallelism, optimal memory management, and automatic garbage collection. It is particularly well-suited for multi-modal AI applications. Finally, NOS is built to be modular and extensible. The core components of NOS are:
ModelManager: The Model Manager is responsible for managing and serving AI models with various policies like FIFO and LRU (not implemented). It ensures that the maximum number of concurrent models is not exceeded.- FIFO and LRU (not implemented) eviction policies.
- Control the maximum number of concurrent models.
- Load, add, and evict models as needed.
- Prevent Out-Of-Memory errors with automatic model cleanup.
-
ModelHandle:TheModelHandleis the core component for serving AI models. It allows you to interact with and scale models as needed. Each Model Handle can have multiple replicas for parallelism.- Call models directly or submit tasks to replicas.
- Scale models up or down dynamically.
- Submit tasks to specific methods of the model.
- Garbage collect models when they are evicted.
-
InferenceService: Ray-executor based inference service that executes inference requests. -
InferenceRuntimeService: Dockerized runtime environment for server-side remote execution